01
Eval-Gates vor jedem Deploy
Kein Agent geht in Produktion ohne dass eine versionierte Eval-Suite gegen ihn läuft. Regressionen werden im PR sichtbar, nicht erst beim User.
Tavora ist die Plattform für Software-Teams, die KI-Agenten ausliefern wollen — kontrollierbar, beobachtbar, mit Eval-Gates vor jedem Deployment. Aus dieser täglichen Bau-Realität speist sich auch meine Beratung für Software-Teams.
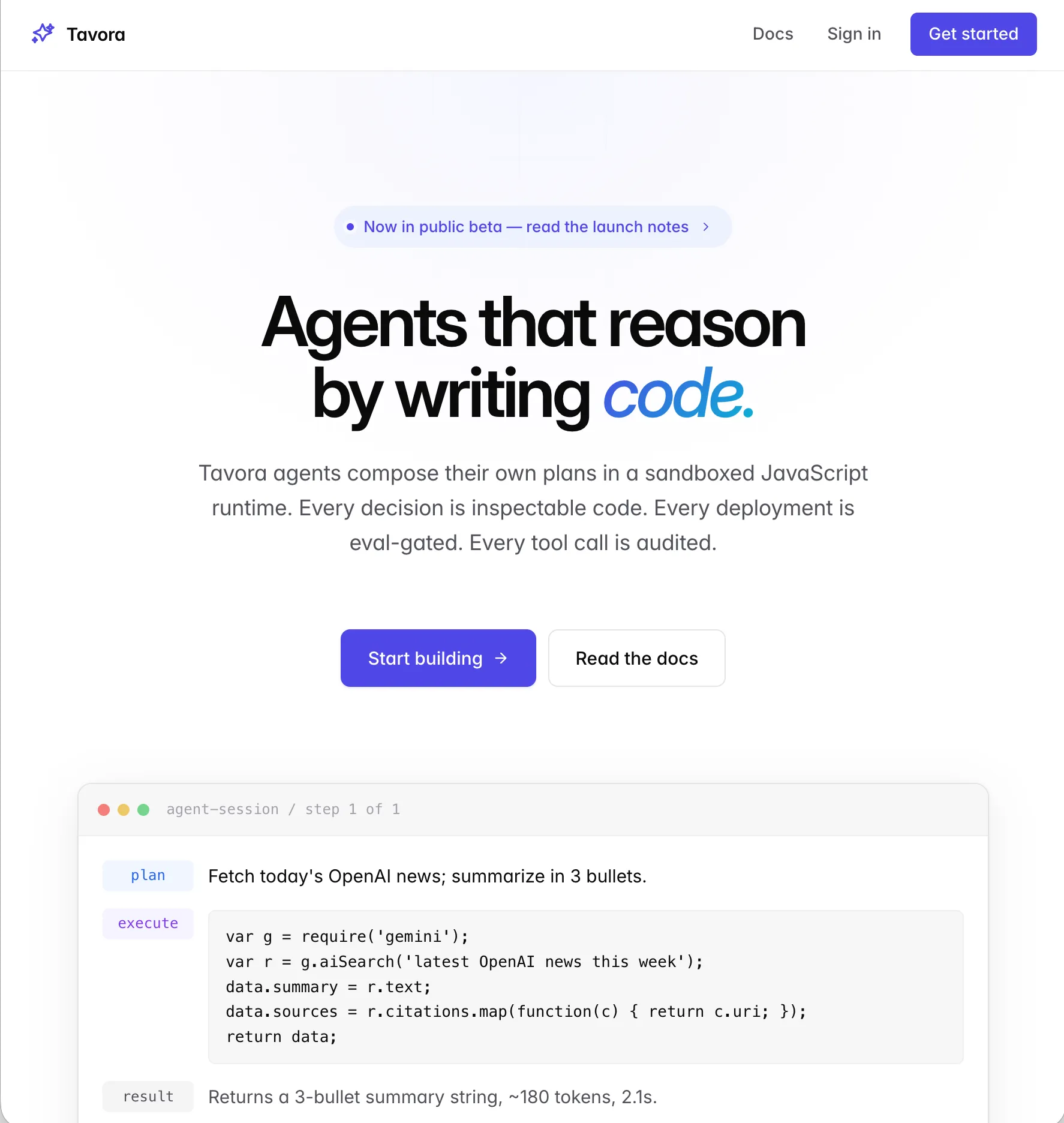
KI-Agenten unterscheiden sich von normaler Software in mindestens vier Punkten gleichzeitig: Sie sind nicht-deterministisch, sie verändern echte Systeme über Tool-Calls, sie kosten pro Aufruf echtes Geld, und sie verhalten sich nach jedem Modell-Update potenziell anders. Jede dieser Eigenschaften für sich ist anstrengend. Zusammen bricht das Standard-Software-Engineering, das die meisten Teams betreiben.
Was passiert in der Praxis, wenn ein Software-Team KI-Agenten naiv deployt: Prompt-Änderungen werden ohne Test in Produktion geschoben. Modell-Updates verschlechtern still die Qualität. Tool-Calls eskalieren in Endlosschleifen und produzieren €1.000 Cost-Spikes über Nacht. Halluzinationen erzeugen Production-Bugs, die niemand reproduzieren kann. Das ist nicht 'KI ist halt unzuverlässig' — das ist fehlende Engineering-Disziplin.
Tavora gibt Software-Teams die Disziplin, ohne dass sie sie selbst von Grund auf bauen müssen. Die Plattform hostet Ihre Agenten in Sandboxes, läuft Eval-Suites bei jeder Änderung, gated Deployments hinter messbaren Qualitätskriterien, und liefert Beobachtbarkeit auf Agent- und Tool-Call-Ebene.
Das Kern-Design-Prinzip von Tavora: Ein Agent ist nicht einfach 'ein LLM-Aufruf mit Tools'. Ein Agent ist ein versionierter Software-Artefakt, der durch eine CI/CD-Pipeline läuft, gegen Evals gemessen wird, und nur in Produktion landet, wenn er bestimmte Qualitätskriterien erfüllt. Wie Software-Engineering — nur eben für nicht-deterministische Systeme.
Technisch: Jeder Agent-Run läuft in einer isolierten Sandbox mit klaren Ressourcen-Limits. Tool-Calls werden zentral logged, mit voller Tracability vom User-Request bis zum letzten LLM-Call. Eval-Suites werden gegen einen versionierten Test-Datensatz ausgeführt, mit Diff-Reports zwischen Versionen. Multi-Tenant von Anfang an, mit klaren Isolations-Garantien.
Was wir gelernt haben: Beobachtbarkeit ist nicht Nice-to-Have, sie ist die Voraussetzung für jedes ernsthafte Agent-Deployment. Wer einen Production-Bug bei einem KI-Agenten ohne strukturierte Logs debuggen muss, lernt das nach dem ersten Vorfall.
Kein Agent geht in Produktion ohne dass eine versionierte Eval-Suite gegen ihn läuft. Regressionen werden im PR sichtbar, nicht erst beim User.
Jeder Agent-Run läuft in einer eigenen Sandbox mit Ressourcen-Limits. Eskalierende Tool-Calls können kein anderes Tenant erreichen, kein Cost-Spike kann unbeobachtet wachsen.
Vom User-Request bis zum letzten LLM-Call ist jeder Schritt loggbar und reproduzierbar. Ein Production-Bug ist debugbar, nicht magisch.
Prompts leben in Git, durchlaufen Code-Review, werden gegen Evals gemessen. Sie sind kein 'mal eben in der UI ändern'-Artefakt.
Sie sehen, welcher Agent welche Kosten produziert, mit welchem Modell, in welchem Tenant. Cost-Anomalien werden früh sichtbar, nicht erst auf der Monatsrechnung.
Modell-Wechsel sind eine Konfigurations-Änderung, kein Re-Build. Wenn ein günstigeres Modell die Eval-Suite besteht, schalten Sie um — ohne Code-Änderung.
Prompts gehören in Git, in PRs, in Code-Review. Wer Prompts in einer UI editiert, macht denselben Fehler wie das Editieren von Production-Code in einer Web-Konsole.
Eine Eval-Suite muss in CI laufen und Regressionen blockieren. Eine 'Eval-Tabelle' im Notion ist keine Eval-Suite — sie ist ein gut gemeintes Dokument.
Ein Tool-Call, der in einer Endlosschleife endet, kann über Nacht €10.000 kosten. Cost-Limits pro Run, pro Agent, pro Tenant sind kein Optimierungs-Detail — sie sind eine Sicherheits-Anforderung.
Ich höre zu, stelle Fragen und sage offen, ob und wie ich helfen kann.