01
Eval gates before every deploy
No agent ships to production without a versioned eval suite running against it. Regressions show up in the PR, not at the user.
Tavora is the platform for software teams who want to ship AI agents — controllable, observable, with eval gates before every deployment. The daily reality of building it feeds straight into my consulting for software teams.
AI agents differ from normal software on at least four axes simultaneously: they are non-deterministic, they change real systems via tool calls, they cost real money per call, and they may behave differently after every model update. Each of these alone is hard. Together they break the standard software engineering most teams practice.
What happens when a software team naively deploys AI agents: prompt changes get pushed to production untested. Model updates silently degrade quality. Tool calls escalate into infinite loops and produce €1,000 cost spikes overnight. Hallucinations cause production bugs nobody can reproduce. That's not 'AI is unreliable' — it's missing engineering discipline.
Tavora gives software teams that discipline without forcing them to build it from scratch. The platform hosts your agents in sandboxes, runs eval suites on every change, gates deployments behind measurable quality criteria, and provides observability at agent and tool-call level.
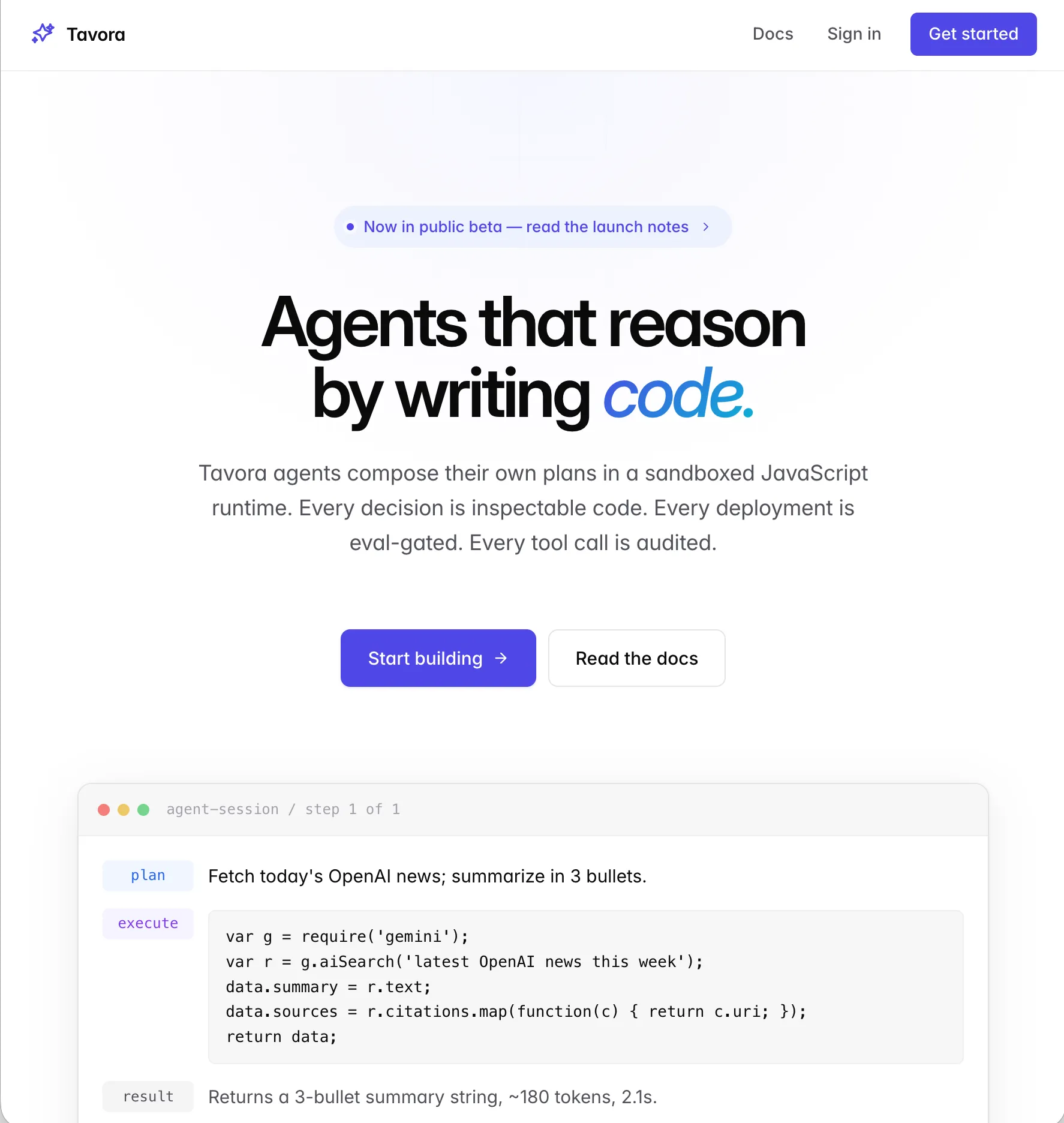
Core design principle of Tavora: an agent is not just 'an LLM call with tools'. An agent is a versioned software artifact that runs through CI/CD, gets measured against evals, and lands in production only when it meets specific quality criteria. Like software engineering — but for non-deterministic systems.
Technically: every agent run executes in an isolated sandbox with clear resource limits. Tool calls are centrally logged, with full traceability from user request to the last LLM call. Eval suites run against a versioned test set, with diff reports between versions. Multi-tenant from day one, with clean isolation guarantees.
What we learned: observability is not nice-to-have — it is the precondition for any serious agent deployment. Anyone who has had to debug a production bug in an AI agent without structured logs learns this after the first incident.
No agent ships to production without a versioned eval suite running against it. Regressions show up in the PR, not at the user.
Every agent run executes in its own sandbox with resource limits. Escalating tool calls can't reach another tenant, no cost spike grows unobserved.
From user request to the last LLM call, every step is loggable and reproducible. A production bug is debuggable, not magical.
Prompts live in Git, go through code review, get measured against evals. Not a 'quickly tweak in the UI' artifact.
You see which agent produces which costs, on which model, in which tenant. Cost anomalies surface early, not on the monthly invoice.
Model swaps are a config change, not a rebuild. If a cheaper model passes the eval suite, you switch — without code change.
Prompts belong in Git, in PRs, in code review. Editing prompts in a UI is the same mistake as editing production code in a web console.
An eval suite must run in CI and block regressions. An 'eval table' in Notion is not an eval suite — it's a well-meant document.
A tool call that ends in an infinite loop can cost €10,000 overnight. Cost limits per run, per agent, per tenant are not an optimization detail — they are a safety requirement.
I listen, ask questions, and tell you honestly whether and how I can help.